Tahoe Therapeutics Raises $30M to Build Billion-Cell Dataset for AI Drug Discovery
August 15, 2025
by

A New Foundation for Virtual Cell Models
Tahoe Therapeutics, the South San Francisco startup building virtual models of human cells, has closed a $30 million Series A to supercharge data generation and accelerate AI-driven drug discovery. The company - founded by CEO Nima Alidoust, CSO Johnny Yu, and scientific cofounders Hani Goodarzi and Kevan Shokat - plans to create one billion single-cell datapoints mapping one million drug-patient interactions, then share the resulting dataset with a single strategic partner to drive real clinical programs.
Why This Round Matters
Most AI-biotech efforts still rely on sparse or proxy data. Tahoe is taking the opposite approach: generate the definitive, high-resolution perturbational dataset and train foundation models on it, so the models learn how chemistry perturbs biology across diverse cellular contexts. The team has already open-sourced Tahoe-100M - a gigascale dataset of ~100 million cells spanning ~60,000 drug-cell interactions - which has been downloaded nearly 100,000 times by researchers and AI labs. The Series A scales that playbook by an order of magnitude.
The Playbook Behind the Raise
Tahoe’s strategy blends in-house data generation with model training and selective access. Rather than compete on me-too models, they’re building the raw material required for state-of-the-art biological foundation models. That advantage compounds: each new batch of perturbational single-cell data improves the model’s ability to generalize across tissues, drugs, and patient-like variation - exactly the context where most models fail to translate.
Here’s the under-the-hood move founders will appreciate: Tahoe treats data as core IP and CapEx, not a byproduct. By aligning wet-lab throughput, sequencing economics, and downstream model objectives, they eliminate the typical handoff friction between biology and ML. Just as text unlocked language models, perturbational single-cell data becomes the enabling substrate for virtual cell models - foundation models that infer gene function and predict drug response in realistic contexts. This is what allows Tahoe to replace trial-and-error screening with model-guided design and to prioritize programs with a better shot at clinical success.
Critically, Tahoe also engineers scarcity with purpose. By selecting a single partner for privileged access to the billion-cell dataset, they align incentives for co-development and measurable clinical readouts, rather than spreading value too thin across many pilots. That focus turns the dataset into operating leverage - one that can move a therapy from in-silico hypothesis to in-vivo validation faster, with lower risk.
Product, Tech, and Moat
The company’s earlier Tahoe-100M mapped responses across 50 cancer cell lines and >1,100 drug perturbations, creating a perturbation atlas that dwarfed public alternatives by orders of magnitude. Scaling to one billion profiles pushes beyond incremental accuracy into new capability: modeling heterogeneity, resistance mechanisms, and context-specific gene function that smaller datasets miss. That’s a moat built on data generation, quality control, and fit-for-purpose labeling, not just model weights.
Tahoe’s roadmap includes Virtual Cell Models and tooling (e.g., TahoeDive) that make those models usable by biologists and drug hunters. The stack integrates experimental design, single-cell sequencing, and model training such that every assay both answers a question and improves the model. It’s an active-learning engine embedded in a wet-lab.
Market Timing
Clinical development remains bottlenecked by translation: molecules that look great in structure or bulk assays often fail in patients. Foundation models trained on cell-level perturbational data promise a different path - predictive, context-aware models that prioritize compounds with higher probability of clinical effect. For oncology and other complex diseases with many subtypes, that’s a meaningful path to precision medicines rather than one-size-fits-all trials.
Who Backed Tahoe’s Series A
The round was led by Amplify Partners, with participation from Databricks Ventures, Wing Venture Capital, General Catalyst, Civilization Ventures, Conviction, Mubadala Capital Ventures, Overlap Holdings, and AIX Ventures. The investor mix reflects a convergence of deep tech, data infrastructure, and biotech expertise - exactly the coalition needed to scale both gigascale assays and frontier models.
What’s Next
With fresh capital, Tahoe will expand data generation to the billion-cell mark, continue advancing its internal oncology programs, and formalize a single-partner collaboration to demonstrate clinical proof. If successful, this approach could reshape how pipelines are built: start with a cell-level foundation model, design interventions predicted to move patient-relevant biology, and let the data flywheel compress the time from hypothesis to trial. In a field crowded with AI claims, Tahoe is betting - and building - on the only thing that ultimately matters: data with causal signal at scale.
Related Articles

Latest Rounds
November 30, 2025 by 
EcoG Raises $18.57M to Accelerate the Operating System for the Global EV Charging Economy
EcoG has raised $18,573,280 in new funding, led by GET Fund with participation from Extantia Capital and Bayern Kapital. Founded...
Read More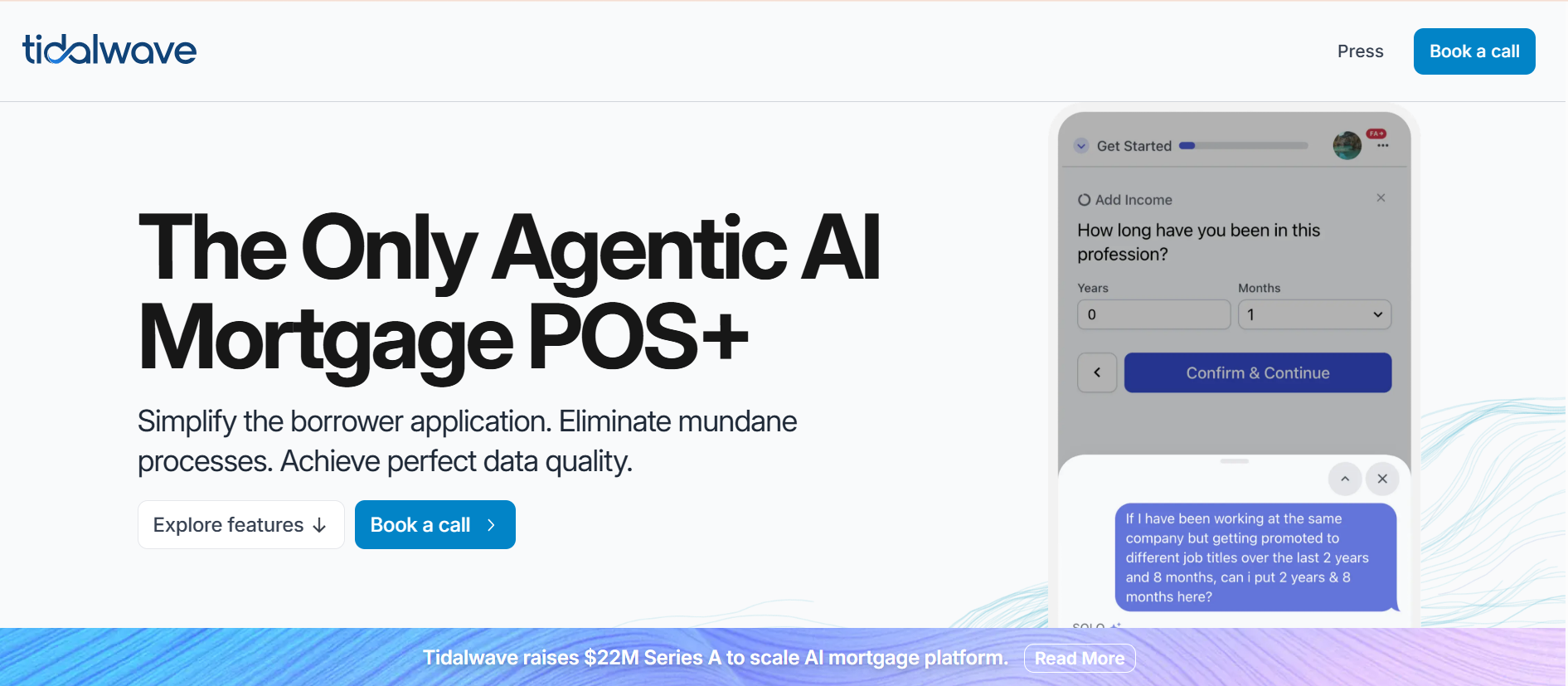
Latest Rounds
November 30, 2025 by
Tidalwave Raises $22M Series A to Build the Infrastructure Layer Modern Homebuilders Need for AI-Driven Operations
Tidalwave has raised $22,000,000 in their Series A, led by Permanent Capital with participation from D.R. Horton, Inc. and Engineering...
Read More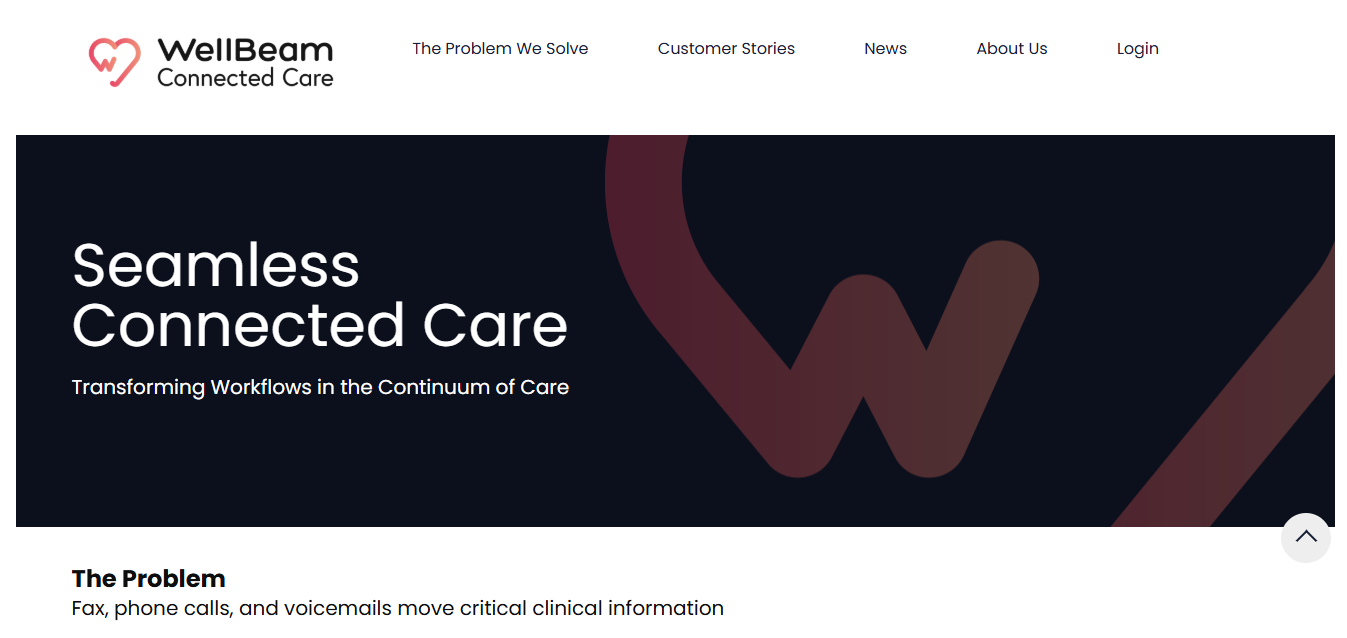
Latest Rounds
November 30, 2025 by 
WellBeam Raises $10M to Unify Care Coordination Across the Entire Patient Journey
WellBeam Inc. has secured $10 million in Series A funding, marking a major step toward fixing one of the most...
Read More
Latest Rounds
November 30, 2025 by
Automat Raises $15.5M to Redefine Industrial Automation With Adaptive AI
Automat has secured $15.5 million in Series A funding, a major milestone for a company working to radically transform how...
Read More
Latest Rounds
November 30, 2025 by
Poly Raises $8M to Reinvent How People Organize, Search, and Think With Their Files
Poly (US) has closed an $8,000,000 Seed round, marking a decisive moment for one of the most ambitious productivity startups...
Read More
Latest Rounds
November 30, 2025 by
Voio Raises $8.6M to Power AI That Understands Patients as Individuals, Not Data Points
Voio has secured $8.6 million in Seed funding, marking a major step forward for a company working to bring true...
Read More
Latest Rounds
November 30, 2025 by
Ember Raises $4.3M to Reinvent AI-Driven Revenue Cycle Management for Healthcare Providers
Ember has secured $4.3 million in Seed funding, marking a major step toward transforming one of healthcare’s most expensive, error-prone,...
Read More
Latest Rounds
November 30, 2025 by
Modern Life Raises $20M to Redefine Life Insurance Infrastructure With AI-Powered Tools for Advisors
Modern Life has secured $20 million in new funding, marking another major milestone in its mission to rebuild the fractured,...
Read More
Latest Rounds
November 30, 2025 by
Ampersand Raises $80M to Power the Next Era of High-Performance Materials
Ampersand has secured a major $80 million Series A round, positioning itself as one of the most significant deep-tech companies...
Read More
Latest Rounds
November 30, 2025 by
OpenHands Raises $18.8M to Bring Autonomous Coding Agents Into the Enterprise
OpenHands has raised $18.8 million in Series A funding, marking one of the strongest signals yet that autonomous software development...
Read More